Глава 2 Проектирование процессоров и компиляторов (LLVM)
В этой главе рассматриваются соответствующие концепции и идеи, касающиеся архитектуры ЦП (центральный процессор) и компилятора.
2.1 Дизайн процессора
Две известные методологии проектирования ЦП с сокращенным набором команд компьютера (RISC) и компьютер с полным набором команд (CISC). Хотя не существует определенного стандарта для разделения определенных архитектур ЦП на эти две категории, обычно большинство архитектур легко классифицируются в одну или в другую сторону в зависимости от их определяющих характеристик.
Одним из ключевых показателей того, что архитектура принадлежит к RISC или CISC, является количество инструкций ЦП, наряду со сложностью инструкций. Архитектуры RISC известны тем, что имеют относительно небольшое количество инструкций, которые обычно выполняют только одну или две операции в одном такте цикла. Однако архитектуры CISC известны тем, что имеют большое количество инструкций, которые обычно выполняют несколько сложных операций за несколько тактов [1]. Например, набор команд ARM содержит около 50 инструкций [2]. В то время как набор команд Intel x86-64 содержит более 600 инструкций [3]. Этот простой контраст подчеркивает основные цели проектирования двух категорий процессоров; RISC архитектуры, как правило, направлены на более низкую сложность в архитектуре и аппаратном дизайне, чтобы сместить сложность в сторону программного обеспечения, и CISC архитектуры стремятся сохранить большую часть сложности в аппаратном обеспечении с целью упрощения реализации программного обеспечения. В то время как это может показаться полезным переход в сторону сложности аппаратного обеспечения, это также вызывает аппаратную проверку, чтобы увеличить сложность. Это может привести к ошибкам в аппаратном дизайне, которые гораздо сложнее исправить по сравнению с ошибками, найденными в программном обеспечении [4].
Некоторые из других показателей RISC или CISC – это количество режимов адресации и формат самих слов инструкции. В целом, использование меньшего количества режимов адресации наряду с последовательным форматом инструкций приводит к более быстрой и менее сложной логике управляющего сигналом [5]. Кроме того, исследование в [6] показывает, что только в логике вычисления адресов может быть до 4× кратного увеличение структурной сложности для процессоров CISC по сравнению с RISC. Обоснование выбора конструкции процессора меняются на протяжении последних нескольких десятилетий. Раньше сложность аппаратного обеспечения, площадь микросхемы и количество транзисторов были одними из основных соображений проектирования. В последние годы, однако, фокус переключился к уменьшению потребляемой электроэнергии и мощности при увеличении скорости. Исследования в [7] установили, что существует аналогичное общую производительность сопоставимы между RISC и архитектуры CISC, хотя CISC – процессоры, как правило, требуют больше энергии.
Есть много вариантов дизайна, участвующих в разработке процессора, направленных исключительно на производительность оборудования. Однако для программного обеспечения, чтобы работать на ЦП есть дополнительные соображения, которые должны быть сделаны. Некоторые из этих соображений включают количество классов регистра, какие типы режимов адресации реализовать, и расположение области памяти.
2.2 Проектирование компилятора
В своем простейшем определении компилятор принимает программу, написанную на каком-либо исходном языке, а затем переводит ее в программу с эквивалентной функциональностью на машинный язык (язык процессора) [8]. Хотя существуют различные варианты процесса компиляции (например, интерпретаторы и компиляторы justin-time (JIT)), в этой статье основное внимание уделяется стандартным компиляторам, в частности тем, которые могут принимать входные программы, написанные на языке C, а затем выводить либо код сборки или машины целевой архитектуры. Рассматривая C в качестве исходного языка, два набора компиляторов действительно считают достаточно зрелыми и оптимизированным для решения современных проблем с программным обеспечением: GCC (Коллекция компиляторов GNU) и LLVM. Несмотря на схожесть функций конечных пользователей, GCC и LLVM работают по-разному друг от друга как в архитектуре программного обеспечения, так и в философии организаций.
2.2.1 Двоичный интерфейс приложения
Перед рассмотрением компилятора для целевого объекта должен быть определен двоичный интерфейс приложения (ABI). Это охватывает все подробности о том, как код и данные взаимодействуют с оборудованием процессора. Некоторые из важных вариантов проектирования, которые должны быть сделаны, включают выравнивание различных типов данных в памяти, определение классов регистров (какие регистры могут хранить, какие типы данных) и соглашения о вызовах функций (независимо от того, помещаются ли операнды функций в стек, в регистры или комбинацию обоих) [9]. ABI должен тщательно рассмотреть архитектуру ЦП, чтобы быть уверенным, что каждый из вариантов дизайна физически возможен, и что они эффективно используют аппаратное обеспечение ЦП при наличии нескольких решений проблемы.
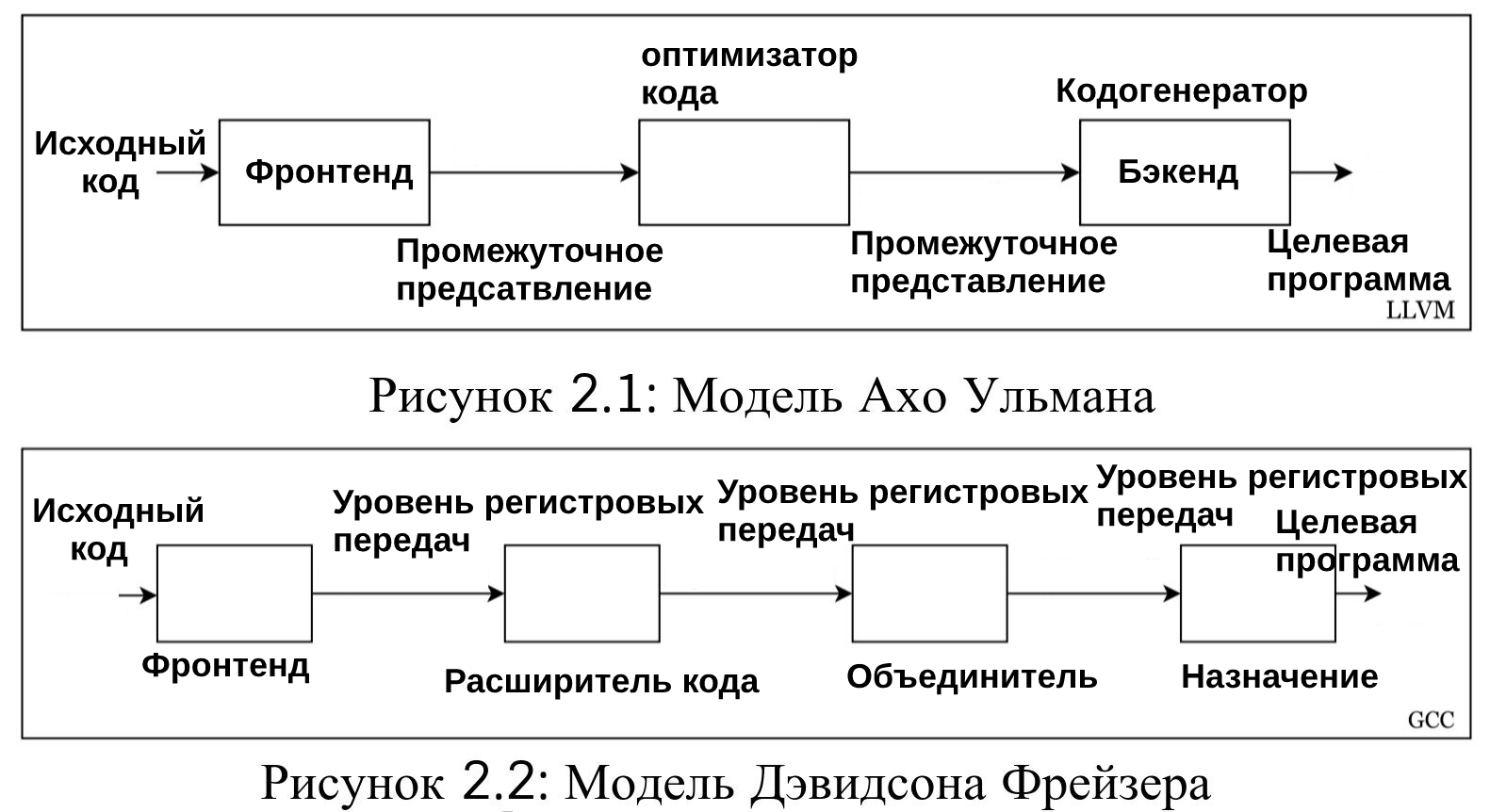
2.2.2 Модели компилятора
Современные компиляторы обычно работают в трех основных фазах: фронтенд, оптимизатор, и бэкенд. Два подхода, как компиляторы должны выполнить эту задачу, являются подход Ахо-Ульмана [8] и подход Дэвидсона-Фрейзера [10]. Блок схемы для каждой из этих моделей показаны на рис. 2.1 и рис. 2.2. Хотя функции эти между собой, эти модели имеют существенные отличия в том, как они выполняют процесс оптимизации и генерации кода.
Модель Ахо-Ульмана уделяет большое внимание использованию целевого языка промежуточного представления (intermediate representation – IR) для основной части оптимизации перед бэкенд частью, что позволяет процессу выбора инструкций использовать подход, основанный на затратах. Модель Дэвидсона Фрейзера направлена на преобразование IR в целевой независимый тип “регистр языка перевода” (язык перевода (RTL) не следует путать с абстракцией дизайна уровня передачи регистров (RTL), используемой для проектирования цифровой логики). RTL затем проходит процесс расширения с последующим распознавателем, который выбирает инструкции на основе расширенного представления [9]. Данная статья посвящена модели Ахо Ульмани, как инструмент LLVM сконструирован с использованием этой методики.
На каждом этапе модели Ахо Ульмана компилятор осуществляет перевод исходной программы в разные представления, которые приносит программа, делая этот этап более близкая к машинному (целевому) языку. Существует существенные преимущества у компилятора разработанного с использованием этой модели; из-за модульности и определенных границ каждого этапа, новые исходные языки, целевые архитектуры и этапы оптимизации могут быть добавлены или изменены в основном независимо друг от друга. Для нового исходного языка нужно только продумать дизайн фронтенда, такой который на выходе соответствует IR, оптимизацию проходит в основном язык-агностик, так, что пока язык работают только на IR и сохраняет функции программы, и, наконец, генерация кода для новой целевой архитектуры только требует разработки бэкенд части, которая принимает IR и формирует выходной машинный код (как правило в сборке или в качестве машинного кода).
2.2.3 GCC
GCC был впервые выпущен в 1984 году Ричардом Столманом [11]. GCC полностью написана на C и в настоящее время по-прежнему поддерживает большую часть той же архитектуры программного обеспечения, которая существовала в первоначальном выпуске более 30 лет назад. Независимо от этого факта, почти каждый стандартный ЦП имеет порт GCC, ЦП в состоянии использовать данный порт. Даже архитектуры, которые не имеют бэкенд части в исходном дереве GCC, как правило, имеют либо частный выпуск, либо пользовательскую сборку, поддерживаемую третьей стороной; примером одной такой архитектуры является Texas Instruments MSP430 [12]. Хотя GCC является популярным вариантом компилятора, этот документ фокусируется на LLVM вместо GCC, так как LLVM обладает значительно более современной кодовой базой.
2.2.4 Код LLVM
LLVM был первоначально выпущен в 2003 году, исполнитель Chris Lattner [13] – это был дипломный проект на звание магистра. С тех пор компилятор чрезвычайно вырос в полностью полную и открытую инфраструктуру компилятора. Написанный на C++ и охватывающий его объектно – ориентированный характер программирования, LLVM теперь стал богатым набором инструментов и библиотек на основе компиляторов. В то время как LLVM раньше был аббревиатурой “низкоуровневой виртуальной машины”, представляющей ее богатый, виртуальный набор инструкций IR язык, проект вырос, чтобы охватить больший объем проектов и целей и LLVM больше не означает ничего [14]. Существует гораздо меньше архитектур, которые поддерживаются в LLVM по сравнению с GCC, потому что LLVM достаточно нов. Несмотря на это, все еще есть организации, которые предпочитают использовать LLVM в качестве инструмента компилятора по умолчанию над GCC [15, 16]. Оставшаяся часть этого раздела описывает три основных этапа компилятора LLVM.
2.2.4.1 Фронтенд
Отвечает за перевод программы ввода из текста, написанного человеком. Этот этап осуществляется посредством лексического, синтаксического и семантического анализа. Формат вывода фронтенда является IR-код инфраструктуры LLVM, IR – это полностью полный набор виртуальных команд, который имеет операции, подобные архитектурам RISC; однако он полностью типизирован, использует представление статического одиночного назначения (SSA) и имеет неограниченное количество виртуальных регистров. Он достаточно низок, так что его можно легко связать с аппаратными операциями, но он также включает в себя достаточно высокоуровневый поток управления и информацию о данных, чтобы обеспечить сложный анализ и оптимизацию [17]. Все из этих характеристик IR LLVM прибавляет на очень эффективный, машино-независимый оптимизатор.
2.2.4.2 Оптимизация
Оптимизатор отвечает за перевод IR с выходных данных фронтенда в эквивалентную, но оптимизированную программу в IR. Хотя на этом этапе выполняется основная часть оптимизаций; оптимизация может и должна быть завершена на каждом этапе компиляции. Пользователи могут оптимизировать код при его написании до того, как он достигнет фронтенда, а бэкенд может оптимизировать код специально для целевой архитектуры и оборудования.
В целом, есть две основные цели этапа оптимизации: увеличить скорость выполнения целевой программы и уменьшить размер кода целевой программы. Для достижения этих целей оптимизации обычно выполняются в несколько проходов по IR, где каждый проход имеет конкретную цель меньшей области. Один из простых способов организации IR, чтобы помочь в оптимизации через форму SSA. Эта форма гарантирует, что каждая переменная определяется ровно один раз, что упрощает многие оптимизации, такие как устранение мертвого кода, устранение ребер, построение цикла и многое другое [13].
2.2.4.3 Бэкенд
Бэкенд отвечает за перевод программы из IR в машинный код (обычно код сборки или машины). По этой причине этот этап также обычно называют генератором кода. Наиболее сложные задачи, которые решаются на этом этапе – это выбор инструкций и распределение регистров.
Выбор инструкций отвечает за преобразование операций, указанных IR, в инструкции, доступные в целевой архитектуре. Для простого примера, рассмотрим программу, в IR, содержащий логическую операцию NOT. Если целевая архитектура не имеет логического NOT инструкции, но она содержит логическую XOR функцию, селектор инструкций будет нести ответственность за преобразования “NOT” операцию в операцию “XOR – 1”, так как они функционально эквивалентны.
Распределение регистров – это совершенно другая проблема, поскольку IR использует неограниченное количество переменных, а не фиксированное количество регистров. Распределитель регистров назначает переменные в IR регистрам в целевой архитектуре. Компилятору требуется информация обо всех регистрах специального назначения вместе с различными классами регистров, которые могут существовать в целевом объекте. На этом этапе решаются также другие вопросы, такие как упорядочение инструкций, выделение памяти и разрешение относительных адресов. Как только все эти проблемы решены, серверная часть может выдать окончательный целевой код сборки или машинный код.
Часть 1 “Дизайн простого 32 битного RISC ЦПУ и бэкенд LLVM компилятора”.