Глава 4
Дизайн собственного LLVM бэкенда
В этой главе обсуждается структура и дизайн собственной архитектуры ЦП, ориентированной на собственный LLVM бэкенд. В разделе 4.1 обсуждается высокоуровневая структура LLVM, а в разделе 4.2 описывается конкретная реализация собственного бэкенда.
4.1 Структура и инструменты
LLVM отличается от большинства традиционных проектов компиляторов, потому что это не просто набор отдельных программ, а набор библиотек. Все эти библиотеки разработаны с использованием объектно-ориентированного программирования и являются расширяемыми и модульными. Это наряду с его трех этапным подходом (см. раздел 2.2.4) и с его современным дизайном кода, делает его очень привлекательной инфраструктурой компилятора для работы. В этой главе представлен собственный LLVM бэкенд, ориентированный на собственный CJG RISC-процессор, архитектура которого подробно описана в главе 3.
4.1.1 Обзор кода – генератора кода
Генератор кода является одним из многих больших фреймворков, доступных в LLVM. Эта конкретная структура предоставляет множество классов, методов и инструментов, которые помогают преобразовать IR-код LLVM в ориентированный/машинный код [20]. Большая часть базы кода, классов и алгоритмов не зависит от назначения и может использоваться всеми конкретными встроенными ресурсами, которые реализованы в ней. Два основных ориентированных компонента, которые составляют пользовательский бэкенд, являются абстрактным описанием цели и реализацией абстрактного ориентированного описания. Эти целевые компоненты структуры необходимы для каждой конкретной архитектуры в LLVM, а генератор кода использует их по мере необходимости в процессе генерации кода.
Генератор кода разделен на несколько этапов. До этапа планирования инструкций, код организован в базовые блоки, где каждый базовый блок представлен в виде ориентированного ациклического графа (DAG). Базовый блок определяется как последовательность операторов, которые выполняются по порядку, от начала основного блока до конца без возможности ветвления, за исключением окончания[8]. DAG могут быть очень полезными структурами данных для работы с базовыми блоками потому что они обеспечивают простой способ определения, какие значения, используемые в базовом блоке, используются в последующих операциях. Любое значение, которое может использоваться в последующей операции, даже в другом базовом блоке, называют “живым” значением. Когда значение не имеет возможности быть использованным, то говорят, что это “убитое” значение.
Высокоуровневые описания этапов, составляющих генератор кода, представлены ниже:
1. Выбор инструкций — переводит LLVM IR внутри операций, которые могут быть выполнены в наборе команд задачи. Виртуальные регистры в форме SSA (промежуточное представление, используемое компиляторами, в котором каждой переменной значение присваивается лишь единожды) используются для представления назначений данных. Результатом этого этапа являются DAG, содержащие инструкции для конкретных целей (заданий).
2. Планирование инструкций — определяет необходимый порядок инструкций целевой (адресованной) машины из DAG. После определения этого порядка группа DAG преобразуется в список машинных инструкций и уничтожается.
3. Оптимизация машинных инструкций — выполняет платформенные оптимизации в списке машинных инструкций, которые могут дополнительно улучшить качество кода.
4. Распределение регистров — отображает текущую программу, которая может использовать любое количество виртуальных регистров, к той, которая использует только регистры, доступные в целевой архитектуре. На этом этапе также учитываются различные классы регистров и соглашение о вызовах, как определено в ABI.
5. Вставка кода пролога и эпилога — обычно вставляет код, относящийся к настройке (пролог), a затем уничтожение (эпилог) кадра стека для каждого базового блока.
6. Оптимизация конечного машинного кода — выполняет все конечные целевые оптимизации, определенные бэкендом.
7. Кодовая эмиссия (создание кода для конечной платформы) – низкоуровневое представление кода из абстракций машинных инструкций, предоставляемых платформой генератора кода в целевой сборки или машинного кода. Выходные данные этого этапа обычно представляют собой текстовый файл сборки или расширяемый объектный файл в формате ELF.
4.1.2 TableGen
Одним из инструментов LLVM, который необходим для написания абстрактного целевого (объектного) описания, является TableGen (llvm-tblgen). Этот инструмент преобразует целевой файл описания (.td) в C++ код, который используется затем при генерации кода. Его основная цель состоит в том, чтобы свести большие, утомительные описания к более мелким и гибким определениям, которыми легче управлять и легче их структурировать [21]. Основная функциональность TableGen находится в TableGen бэкенде (не путать с llvm бэкендами (генераторами кода для конкретного целевого назначения)). Эти модули отвечают за перевод целевого файлового описания в формат, который может использоваться генератором кода [22]. Генератор кода предоставляет все модули TableGen, необходимые большинству ЦП для выполнения абстрактного описания целевого объекта, однако пользовательские модули TableGen могут быть написаны и для других целей.
Тот же входной код TableGen обычно создает различные выходные зависимости от используемого TableGen бэкенда. Код TableGen, приведенный в листинге 4.1, используется для определения каждого из регистров ЦП, входящих в архитектуру CJG. Бэкенд часть AsmWriter TableGen, отвечающая за создание кода для формирования кода целевой сборки, создает C++ код , приведенный в листинге 4.2. Однако, информация о регистрах часть TableGen бэкенд, которая отвечает за создание кода для описания файла регистра в генераторе кода, генерирует код на языке C++, приведенный в листинге 4.3.
Существует много больших таблиц (например, в строке 7 листинга 4.2) и функций, которые генерируются из TableGen, чтобы помочь в разработке пользовательского интерфейса LLVM. Хотя в настоящее время TableGen отвечает за основную часть описания целевого объекта, для завершения реализации абстрактного описания целевого объекта по-прежнему требуется написать большой объема кода на языке C++. По мере развития LLVM, цель состоит в том, чтобы переместить, как можно больше целевого описания в форму TableGen [20].
// Регистры специального назначения
def SR : CJGReg<0, "r0">;
def PC : CJGReg<1, "r1">;
def SP : CJGReg<2, "r2">;
// Регистры общего назначения
foreach i = 3-31 in {
def R#i : CJGReg< #i, "r"##i>;
}
Листинг 4.1: Определения наборов регистров TableGen
/// getRegisterName - этот метод автоматически генерируется с помощью tblgen
/// из описания набора регистров. Возвращает имя ассемблера
/// для указанного регистра.
const char *CJGInstPrinter::getRegisterName(unsigned RegNo) {
assert(RegNo && RegNo < 33 && "Invalid register number!");
static const char AsmStrs[] = {
/* 0 */ 'r', '1', '0', 0,
/* 4 */ 'r', '2', '0', 0,
...
};
...
}
Листинг 4.2: Вывод TableGen AsmWriter
namespace CJG {
enum {
NoRegister,
PC = 1,
SP = 2,
SR = 3,
R3 = 4,
R4 = 5,
...
};
} // end namespace CJG
Листинг 4.3: Вывод Tablegen RegisterInfo
4.1.3 Clang и llc
Clang (произносится «клэнг») – это фронтенд для LLVM, который поддерживает C, C++ и Objective C/C++ [23]. Clang отвечает за функциональность, описанную в разделе 2.2.4.1. Инструмент llc – это статический компилятор LLVM, который отвечает за функциональность, описанную в разделе 2.2.4.3. Пользовательские модули, написанные для LLVM, связаны в llc, которые затем компилируется IR-кодом LLVM для целевой сборки или машинного кода.
4.2 Внедрение пользовательских целей
Пользовательский бэкенд LLVM наследует и расширяет многие классы LLVM. Для реализации бэкенд части LLVM большинство файлов размещаются в каталоге lib/Target/TargetName/, где TargetName – это имя целевой архитектуры, на которую ссылается LLVM. Это имя важно и должно оставаться неизменным на протяжении всей разработки бэкенд части, так как оно используется внутренними компонентами LLVM для поиска пользовательской бэкенд части. Имя для этой целевой архитектуры было выбрано, как CJG, поэтому пользовательский бэкенд находится в lib/Target/CJG/. “Точка входа” бэкенд части CJG LLVM находится в пределах CJGMCTargetDescription. Это место, где бэкенд часть зарегистрирована в LLVM TargetRegistry, так что LLVM мог найти и использовать эту бэкенд часть. График который показан на рис. 4.1 дает четкое представление о классах и файлах, которые являются частью бэкенд части CJG. В дополнение к модулям RISC-процессоров, которые в настоящее время находятся в llvm с дерева исходных текстов (а именно ARM и msp430), некоторые архитектуры использовались как примеры и как ресурсы в ходе реализации CJG бэкенда: Cpu0 [24], LEG [25], и RISC-V в [26]. Остальная часть этого раздела описывает детали реализации пользовательского CJG LLVM бэкенда.

Рисунок 4.1: График включения CJGMCTargetDesc.h
4.2.1 Абстрактное описание задачи
Как описано в разделе 4.1.2, большая часть абстрактного описания задачи написана в формате TableGen. Основные компоненты CJG бэкенд части написана в форме TableGen, в форме сведений об регистрах, специальных операндов, в формате вызовов, инструкций и в формате полных инструкции определения. В дополнение к компонентам TableGen, есть некоторые моменты, которые должны быть написаны на C++. Эти компоненты абстрактного целевого описания описаны в следующих разделах.
4.2.1.1 Информация о регистрах
Информация о регистре находится в CJGRegisterInfo.td. Этот файл определяет набор регистров CJG RISC, а также различные классы регистров. Это упрощает разделение регистров, которые могут содержать только определенный тип данных (например, целочисленные классы и классы регистров с плавающей запятой). Поскольку архитектура CJG не поддерживает операции с плавающей запятой, основным классом регистра является класс регистра общего назначения. Определение этого класса приведен в листинге 4.4. Определение каждого отдельного регистра находится в этом файле и показано в листинге 4.1.
// Класс регистров общего назначения
def GPRegs : RegisterClass<"CJG", [i32], 32, (add
(sequence "R%u", 4, 31), SP, R3
)>;
Листинг 4.4: Определение класса регистров общего назначения
4.2.1.2 Соглашение о вызовах
Определение соглашения о вызовах описывают часть ABI, которая управляет перемещением данных между вызовами функций. Определение соглашения о вызовах определены в CJGCallingConv.td и определение соглашения о возвратных вызовах приведены в листинге 4.5. Это определение описывает, какие значения возвращает функция. Во-первых, любые 8-битные или 16-битные значения должны быть преобразованы в 32-разрядное значение. Затем первые 8 возвращаемых значений помещаются в регистры R24-R31. Все остальные возвращаемые значения будут помещены в стек данных.
//===------------------------------------------------------------------===//
// Соглашение о вызове возвращаемого значения CJG
//===------------------------------------------------------------------===//
def RetCC_CJG : CallingConv<[
// Повысьте аргументы i8/i16 до i32, сделать преобразование типа данных.
CCIfType<[i8, i16], CCPromoteToType<i32>>,
// i32 возвращаются в регистры R24-R31
CCIfType<[i32], CCAssignToReg<[R24, R25, R26, R27, R28, R29, R30, R31]>>,
// Целочисленные значения сохраняются в слотах стека размером 4 байта
// размер и 4-байтовое выравнивание.
CCIfType<[i32], CCAssignToStack<4, 4>>
]>;
Листинг 4.5: Определение соглашения о возвратных вызовах
4.2.1.3 Специальные операнды
Существует несколько специальных типов операндов, которые должны быть определены в рамках целевой архитектуры. Есть много операндов, которые предопределены в TableGen, такие как i16imm и i32imm (определенный в include/llvm/Target/Target.td), однако, бывают случаи, когда этого недостаточно. Два примера специальных операндов, которые должны быть определены, являются операндом адреса памяти и операндом кода условия перехода. Оба этих операнда должны быть определены отдельно, поскольку они не являются стандартными размерами типа данных и должны иметь специальные методы для формирования их в сборке. Пользовательский операнд memsrc содержит регистр и немедленное значение для режима индексированной адресации (как показано в таблице 3.2). Эти определения находятся в CJGInstrInfo.td и показаны в листинге 4.6. PrintMethod и EncoderMethod определяют имена пользовательских функций C++, которые будут вызываться при формировании операнда в сборке или кодировании операнда в машинном коде.
// Адресный операнд для режима индексированной адресации
def memsrc : Operand<i32> {
let PrintMethod = "printMemSrcOperand";
let EncoderMethod = "getMemSrcValue";
let MIOperandInfo = (ops GPRegs, CJGimm16);
}
// Операнд для печати кода условия.
def cc : Operand<i32> {
let PrintMethod = "printCCOperand";
}
Листинг 4.6: Определения специальных операндов
4.2.1.4 Формат инструкций
Форматы инструкций описывают форматы слов инструкций согласно форматам, описанным в разделе 3.3 наряду с некоторыми другими важными свойствами. Эти форматы определены в CJGInstrFormats.td. Базовый класс для всех форматов команд CJG показан в листинге 4.7. Затем он расширяется в несколько других классов для каждого типа инструкции. Например, определения формата инструкции АЛУ для режимов регистр-регистр и регистр-мгновенного перехода показаны в листинге 4.8.
//===------------------------------------------------------------------===//
// Формат инструкции суперкласс
//===------------------------------------------------------------------===//
class InstCJG<dag outs, dag ins, string asmstr, list<dag> pattern>
: Instruction {
field bits<32> Inst;
let Namespace = "CJG";
dag OutOperandList = outs;
dag InOperandList = ins;
let AsmString = asmstr;
let Pattern = pattern;
let Size = 4;
// определить код в базовом классе, потому что все инструкции имеют одинаковый
// битовый размер и битовое расположение для опкода
bits<5> Opcode = 0;
let Inst{31-27} = Opcode; //установить верхний 5 бит для кода операции
}
// CJG формат псевдо-инструкций
class CJGPseudoInst<dag outs, dag ins, string asmstr, list<dag> pattern>
: InstCJG<outs, ins, asmstr, pattern> {
let isPseudo = 1;
let isCodeGenOnly = 1;
}
Листинг 4.7: определение базовой инструкции CJG
4.2.1.5 Полное определение инструкций
Полные определение инструкций наследуется от формы класса, чтобы завершить базовый класс TableGen. Эти завершающие инструкции определены в CJGInstrInfo.td. Некоторые определения инструкций АЛУ приведены в листинге 4.9. Функциональность нескольких классов упрощает определение нескольких очень похожих инструкций
//===------------------------------------------------------------------===//
// Инструкции АЛУ
//===------------------------------------------------------------------===//
// Регистр-регистр ALU-инструкция
class ALU_Inst_RR<bits<5> opcode, dag outs, dag ins, string asmstr,
list<dag> pattern>
: InstCJG<outs, ins, asmstr, pattern> {
bits<5> ri; // регистр назначения
bits<5> rj; // источник регистра 1
bits<5> rk; // источник регистра 2
let Opcode = opcode;
let Inst{26-22} = ri;
let Inst{21-17} = rj;
let Inst{16-12} = rk;
let Inst{11-1} = 0;
let Inst{0} = 0b0; // контрольный бит для немедленного режима
}
// Регистр АЛУ-немедленная инструкция
class ALU_Inst_RI<bits<5> opcode, dag outs, dag ins, string asmstr,
list<dag> pattern>
: InstCJG<outs, ins, asmstr, pattern> {
bits<5> ri; // регистр назначения
bits<5> rj; //источник регистра 1
bits<16> const; // константа / немедленное значение
let Opcode = opcode;
let Inst{26-22} = ri;
let Inst{21-17} = rj;
let Inst{16-1} = const;
let Inst{0} = 0b1; // контрольный бит для немедленного режима
Листинг 4.8: определения формата базовых инструкций ALU
друг на друга. В этом случае инструкции АЛУ регистр-регистр (rr) и регистр-непосредственного передохода (ri) определяются в рамках мультикласса. При использовании ключевого слова defm определяются все классы в мультиклассе (например, определение инструкции ADD в строке 23 листинга 4.9 расширяется в определение инструкций ADDrr и ADDri).
//===------------------------------------------------------------------===//
// Инструкции АЛУ
//===------------------------------------------------------------------===//
let Defs = [SR] in {
multiclass ALU<bits<5> opcode, string opstr, SDNode opnode> {
def rr : ALU_Inst_RR<opcode, (outs GPRegs:$ri),
(ins GPRegs:$rj, GPRegs:$rk),
!strconcat(opstr, "\t$ri, $rj, $rk"),
[(set GPRegs:$ri, (opnode GPRegs:$rj, GPRegs:$rk)),
(implicit SR)]> {
}условной инструкции для завершенного перехода
def ri : ALU_Inst_RI<opcode, (outs GPRegs:$ri),
(ins GPRegs:$rj, CJGimm16:$const),
!strconcat(opstr, "\t$ri, $rj, $const"),
[(set GPRegs:$ri, (opnode GPRegs:$rj, CJGimm16:$const)),
(implicit SR)]> {
}
}
defm ADD : ALU<0b01000, "add", add>;
defm SUB : ALU<0b01001, "sub", sub>;
defm AND : ALU<0b01100, "and", and>;
defm OR : ALU<0b01110, "or", or>;
defm XOR : ALU<0b01111, "xor", xor>;
defm MUL : ALU<0b11010, "mul", mul>;
defm DIV : ALU<0b11011, "div", udiv>;
...
} //пусть Defs = [SR]
Листинг 4.9: завершенные определения инструкций ALU
В дополнение к опкоду, эти определения также содержат некоторую другую чрезвычайно важную информацию для LLVM. Например, рассмотрим определение ADDri. Поля outs и ins в строках 15 и 16 листинга 4.9 описывают источник и назначение выходов и входов каждой инструкции. Строка 15 описывает, что инструкция выводит одну переменную в класс регистра GPRegs и она хранится в переменной ri класса (определенной в строке 10 листинга 4.8). В строке 16 листинга 4.9 описывается, что инструкция принимает два операнда; первый операнд принимается из класса регистра GPRegs, а второй определяется пользовательский тип операнда CJGimm16. Первый операнд хранится в переменной rj класса, а второй – в переменной rk класса. Строка 17 показывает определение сборочной строки; переменная opstr передается в класс как параметр, а переменные класса ссылаются на символ $. Строки 18 и 19 описывают шаблон инструкции. Вот как генератор кода в конечном итоге может выбрать эту инструкцию из LLVM IR. Параметр opmode передается из третьего параметра объявления defm, показанного в строке 23. Тип opnode является классом SDNode, который представляет узел в DAG, используемом для выбора инструкции (назвали SelectionDAG). В данном примере SDNode является add, который уже определен LLVM. Некоторые инструкции, однако, нуждаются в пользовательской реализации SDNode. Этот шаблон будет сопоставлен, если в SelectionDAG есть узел add с двумя операндами, где один является регистром в классе GPRegs и другая константа. Назначение узла также должно быть регистром в классе GPRegs. Еще одна деталь, которая выражается в полных определениях инструкций, – это неявное использование или определение других физических регистров в ЦП. Рассмотрим простую инструкцию по сборке
add r4, r5, r6
где r5 добавляется в r6, а результат сохраняется в r4. Говорят, что эта инструкция определяет r4 и использует r5 и r6. Поскольку все инструкции add могут изменять регистр состояния, эта инструкция также неявно определяет SR. Это выражено в TableGen с использованием Defs и implicit ключевых слов и можно увидеть в строках 5, 12 и 19 листинга 4.9. Неявное использование регистра также может быть выражено в TableGen с помощью ключевого слова Uses. Это можно увидеть в определении условной инструкции перехода. Поскольку условная инструкция перехода зависит от регистра состояния, несмотря на то, что регистр состояния не является входом в инструкцию, говорят, что он неявно использует SR. Это определение приведено в листинге 4.10. В этом списке также показано использование пользовательского класса SDNode, CJGbrcc, а также пользовательского операнда cc (определенного в листинге 4.6).
// Условный переход
let isBranch = 1, isTerminator = 1, Uses=[SR] in {
def JCC : FC_Inst<0b00101,
(outs), (ins jmptarget:$addr, cc:$condition),
"j$condition\t$addr",
[(CJGbrcc bb:$addr, imm:$condition)]> {
// установите ri в 0 и управление в 1 для режима абсолютной адресации
let ri = 0b00000;
let control = 0b1;
}
} // isBranch = 1, isTerminator = 1
Листинг 4.10: Определение условной инструкции перехода
4.2.1.6 Дополнительное описание
Есть дополнительные описания, которые еще не были перенесены в TableGen и должны быть реализованы в C++ . Одним из таких примеров является структура CJGRegisterInfo. Зарезервированные регистры ЦП должны быть описаны функцией getReservedRegs. Код этой функции приведен в листинге 4.11
4.2.2 Выбор инструкции
Этап выбора инструкций бэкенд части отвечает за перевод IR-кода LLVM в специализированные машинные инструкции [20]. В этом разделе описываются фазы выбора инструкций.
BitVector CJGRegisterInfo::getReservedRegs(const MachineFunction &MF) const {
BitVector Reserved(getNumRegs());
Reserved.set(CJG::SR); // регистр состояния
Reserved.set(CJG::PC); // счетчик команд
Reserved.set(CJG::SP); // указатель стека
return Reserved;
}
Листинг 4.11: Реализация описания зарезервированных регистров
4.2.2.1 Конструкция SelectionDAG
Первым шагом этого процесса является создание недопустимого SelectionDAG из входных данных. SelectionDAG считается недопустимым, если он содержит инструкции или операнды, которые не могут быть представлены на целевом ЦП. Преобразование из LLVM IR в начальный SelectionDAG является жестко закодированным и законченным фреймворком генератора кода. Рассмотрим пример функции, myDouble, которая принимает целое число в качестве параметра и возвращает ввод, два раза. Реализация кода C для этой функции, myDouble, показана в листинге 4.12, а эквивалентный код LLVM IR показан в листинге 4.13.
int myDouble(int a) {
if (a == 0) {
return 0;
}
return a + a;
}
Листинг 4.12: Реализация myDouble C
Как описано в разделе 4.1.1, для каждого базового блока кода создается отдельный SelectionDAG. Как обозначено метками (entry, if.then, и if.end)) в листинге 4.13 эта функция содержит три основных блока. Начальный SelectionDAG, построенный для каждого базового блока в IR-коде LLVM для myDouble, показан на рис. 4.2, 4.3 и 4.4. Каждый
define i32 @myDouble(i32 %a) #0 {
entry:
%cmp = icmp eq i32 %a, 0
br i1 %cmp, label %if.then, label %if.end
if.then: ; preds = %entry
ret i32 0
if.end: ; preds = %entry
%add = add nsw i32 %a, %a
ret i32 %add
}
Листинг 4.13: IR-код myDouble LLVM
узел графика представляет собой экземпляр класса SDNode. Каждый узел обычно содержит код операции для указания конкретной функции узла. Некоторые узлы хранят значения только в том случае, если другие узлы работают со значениями из узлов соединения. В фигурах SelectionDAG входы в узлы перечисляются в верхней части узла, а выходы выводятся снизу. SelectionDAG может представлять как поток данных, так и управление потоком зависимостей. Рассмотрим SelectionDAG, показанный на рисунке 4.2. Сплошные стрелки (например, соединительный узел t1 и t2) представляют зависимость от потока данных. Однако пунктирные стрелки (например, соединение t0 и t2) представляют зависимость от управляющего потока. Зависимости потока данных сохраняют данные, которые должны быть доступны для непосредственного использования в будущей операции, а также зависимости управления потока сохраняют порядок между узлами, которые имеют побочные эффекты (такие как ветвление/прыжки) [20]. Зависимости управляющего потока называются ребрами цепей (chain) и могут быть видны на фигурах SelectionDAG, поскольку пунктирные стрелки, соединяющиеся с узлом «ch», выводятся на вход их зависимого узла. Иногда требуется настраивать зависимость для конкретных операций. Они могут быть заданы с помощью зависимостей связности, которые могут помочь разделить узлы в планировании. Это видно на рисунке 4.3 стрелкой, соединяющей вывод «связности» узла t3 с входом 2 узла t4. Это необходимо, потому что любые возвращаемые значения

Рисунок 4.2: Начальная myDouble:entry SelectionDAG
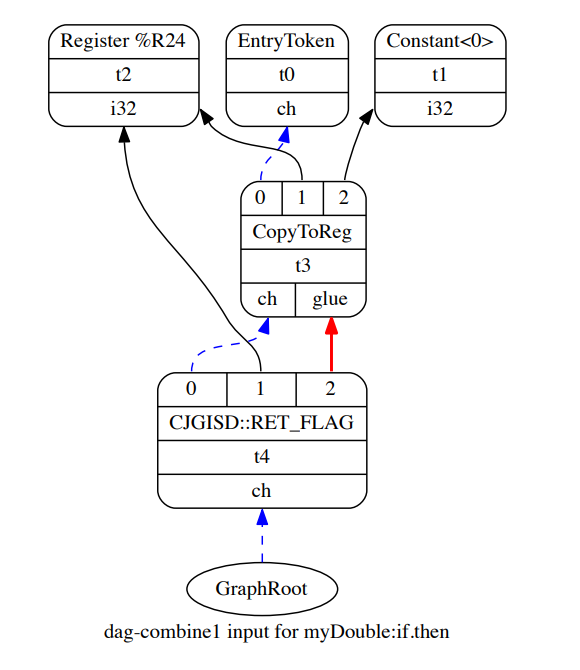
Рисунок 4.3: Начальный myDouble: if.then SelectionDAG

Рисунок 4.4: Начальный myDouble: if.end SelectionDAG
не должны быть нарушенными перед возвратом функции.
4.2.2.2 Оформление
После того, как SelectionDAG изначально сконструирован, любые инструкции LLVM или типы данных, которые не поддерживаются целевым ЦП, должны быть преобразованы или оформлены так, чтобы целая группа DAG могла быть представлена изначально для определенного назначения. Тем не менее, есть некоторые начальные прогоны оптимизации, которые происходят до оформления. SelectionDAG для базового блока myDouble: entry до оформления, после начальных шагов оптимизации их можно увидеть на рисунке 4.5. Сравнивая это с SelectionDAG до оптимизации (см. Рис 4.2), показано, что узлы t4, t5, t6, t7 и t9 были объединены в узлы t12 и t14. Завершение оформления выполняется сразу после проходов оптимизации. Узаконенный SelectionDAG для базового блока myDouble: entry показан на рисунке 4.6. В качестве примера, чтобы показать, как оформление реализовано, рассмотрите формирование узлов SelectionDAG t12 и t14 (см. Рис. 4.5), в узлы t15, t16 и t17 (см. Рис. 4.6). Реализация оформления инструкций включает в себя как описание TableGen, так и пользовательский код C++ для бэкенда. Пользовательские SDNodes сначала определяются в CJGInstrInfo.td. Два пользовательских определения узлов показаны в листинге 4.14. Несмотря на то, что в заголовочном файле LLVM ISDOpcodes.h имеется множество целевых зависимых операций SelectionDAG, инструкции для этого примера требуют целевых операций: CJGISD::CMP (сравнение) и CJGISD::BR_CC (условное отделение). Эти операции определены в CJGISelLowering.h, как показано в листинге 4.15. Еще одно требование – описать коды условий перехода. Требование кодирует информацию, описанную в таблице 3.5, и показано в листинге 4.16. Реализация оформления описана в CJGISelLowering.cpp, как часть пользовательского класса CJGTargetLowering (унаследованного от класса TargetLowering LLVM).

Рисунок 4.5: Оптимизированный myDouble:entry SelectionDAG

Рисунок 4.6: Оформление myDouble:entry SelectionDAG
def CJGcmp : SDNode<"CJGISD::CMP", SDT_CJGCmp, [SDNPOutGlue]>;
def CJGbrcc : SDNode<"CJGISD::BR_CC", SDT_CJGBrCC, [SDNPHasChain,
SDNPInGlue]>;
Листинг 4.14: Пользовательские определение TableGen SDNode
namespace CJGISD {
enum NodeType {
FIRST_NUMBER = ISD::BUILTIN_OP_END,
...
// The compare instruction
CMP,
// Branch conditional, condition-code
BR_CC,
...
};
}
Листинг 4.15: Определения целевых операций SDNode
namespace CJGCC {
// CJG specific condition codes
enum CondCodes {
COND_U = 0, // unconditional
COND_C = 8, // carry
COND_N = 4, // negative
COND_V = 2, // overflow
COND_Z = 1, // zero
COND_NC = 7, // not carry
COND_NN = 11, // not negative
COND_NV = 13, // not overflow
COND_NZ = 14, // not zero
COND_GE = 6, // greater or equal
COND_L = 9, // less than
COND_INVALID = -1
};
}
Листинг 4.16: Кодирование уловного перехода
Пользовательские операции сначала определяются в конструкторе для CJGTargetLowering, который заставляет метод LowerOperation вызываться, когда эти пользовательские операции встречаются. Нижняя операция отвечает за выбор метода класса для вызова каждой пользовательской операции. В этом примере, методаLowerBR_CC, вызывается. Эта часть реализации оформления показана в листинге 4.17.
SDValue CJGTargetLowering::LowerOperation(SDValue Op, SelectionDAG &DAG) const {
switch (Op.getOpcode()) {
case ISD::BR_CC: return LowerBR_CC(Op, DAG);
...
default:
llvm_unreachable("unimplemented operand");
}
}
...
SDValue CJGTargetLowering::LowerBR_CC(SDValue Op, SelectionDAG &DAG) const {
SDValue Chain = Op.getOperand(0);
ISD::CondCode CC = cast<CondCodeSDNode>(Op.getOperand(1))->get();
SDValue LHS = Op.getOperand(2);
SDValue RHS = Op.getOperand(3);
SDValue Dest = Op.getOperand(4);
SDLoc dl (Op);
SDValue TargetCC;
SDValue Flag = EmitCMP(LHS, RHS, TargetCC, CC, dl, DAG);
return DAG.getNode(CJGISD::BR_CC, dl, Op.getValueType(),
Chain, Dest, TargetCC, Flag);
}
Листинг 4.17: Реализация платформенной операции SDNode
Фактическая оформление происходит в методе LowerBR_CC. В строках 11-15 листинга 4.17 показано, как работают значения SDNode (входы узла t14 SelectionDAG показаны на рис. 4.5) хранятся в переменных. Вспомогательный метод EmitCMP (вызывается в строке 19) возвращает SDNode для операции CJG::CMP, а также устанавливает целевую переменную CC в правильный код условия. После того, как эти значения создаются, создаются новые целевые SDNode для этого используется вспомогательный метод getNode, определенный в классе SelectionDAG. Этот узел тогда возвращается через LowerOperation метод и наконец заменяет исходные узлы, t12 и t14, с узлами t15, t16 и t17 (как показано на рис. 4.6).
4.2.2.3 Выбор
Фаза выбора является самой крупной фазой в процессе выбора инструкции [20]. Этот этап отвечает за преобразование оформленного SelectionDAG, состоящего из LLVM и пользовательских операций, в DAG, состоящую из целевых операций. Этап отбора в значительной степени зависит от шаблонов, определенных в описаниях инструкций конкурирования (см. раздел 4.2.1.5). Например, рассмотрим шаблоны инструкций АЛУ, показанные в строках 11 и 18 листинга 4.9, а также шаблон условных инструкций перехода, показанный в строке 6 листинга 4.10. Эти шаблоны используются классом SelectionDAGISel для выбора целевых инструкций. myDouble DAG-ах после этапа выбора показаны на рис. 4.7, 4.8 и 4.9. Шаблоны АЛУ совпали с узлами t1 и t3 из myDouble:if.then SelectionDAG которые показаны на рис. 4.3, в узлы t1 и t5, которые видны в DAG, в DAG показаны на рис.4.3. 4.8. Узел t3 myDouble:if.end SelectionDAG показан на рис. 4.4 также соответствовал шаблону АЛУ. Независимая от цели, операция “add“ была заменена целевой операцией ”ADDrr“, которая видна в узле t3 DAG, которая показана на рис.3. 4.9. Пользовательские операции “CJGISD::СМР” и “CJGISD::BR_CC” используются в узлах t16 и t17 из SelectionDAG, которые показаны на рис. 4.6, а также они сопоставимы. Результирующие целевые операции ”CMPri“ и ”JCC” можно увидеть в узлах t16 и t17 DAG, которые показаны на рис. 4.7. После завершения этого этапа все операции SDNode представляют собой целевые инструкции, и DAG готова к планированию.

Рисунок 4.7: Выбранный myDouble: entry SelectionDAG

Рисунок 4.8: Выбранный myDouble:if.then SelectionDAG

Рисунок 4.9: Выбранный myDouble:if.end SelectionDAG
4.2.2.4 Планирование
Этап планирования отвечает за преобразование DAG инструкций для платформы в список машинных инструкций (представленных экземплярами класса MachineInstr). Планировщик может упорядочить инструкции в зависимости от ограничений, таких как минимизация использования регистров или уменьшение общей задержки исполняемой программы [20]. Как только список машинных инструкций финализирован, DAG завершается. Запланированный список машинных инструкций для функции myDouble приведен в листинге 4.18.
BB#0: derived from LLVM BB %entry
Live Ins: %R4
%vreg0<def> = COPY %R4; GPRegs:%vreg0
CMPri %vreg0, 0, %SR<imp-def>; GPRegs:%vreg0
JCC <BB#2>, 14, %SR<imp-use>
JMP <BB#1>
BB#1: derived from LLVM BB %if.then
Predecessors according to CFG: BB#0
%vreg2<def> = CPYri 0; GPRegs:%vreg2
%R24<def> = COPY %vreg2; GPRegs:%vreg2
RET %R24<imp-use>
BB#2: derived from LLVM BB %if.end
Predecessors according to CFG: BB#0
%vreg1<def> = ADDrr %vreg0, %vreg0, %SR<imp-def,dead>;
GPRegs:%vreg1,%vreg0,%vreg0
%R24<def> = COPY %vreg1; GPRegs:%vreg1
RET %R24<imp-use>
Листинг 4.18: Первоначальный список машинных инструкций для функции myDouble
4.2.3 Распределение регистров
Этот этап бэкенд части отвечает за удаление всех виртуальных регистров из списка машинных инструкций и их замену физическими регистрами. Для простого RISC механизма, это типичная небольшая процедура необходима для функционального распределения регистров. Основной алгоритм, используемый на этом этапе, называется “жадный распределитель регистров“. Главное преимущество этого алгоритма в том, что он сначала выделяет наибольшие диапазоны необходимых переменных [27]. При наличии динамических переменных, которые не могут быть назначены регистру из-за отсутствия доступных, затем они (переменные) записываются/попадают в память. Затем вместо использования физического регистра инструкции load и store вставляются их в список машинных инструкций до и после момента использования значения. Окончательный список машинных инструкций для функции myDouble приведен в листинге 4.19. Окончательное сопоставление регистров приведено в таблице 4.1. После удаления всех виртуальных регистров код может быть перед ассемблеру.
BB#0: derived from LLVM BB %entry
Live Ins: %R4 %SR
PUSH %SR<kill>, %SP<imp-def>
CMPri %R4, 0, %SR<imp-def>
JCC <BB#1>, 1, %SR<imp-use>
BB#2: derived from LLVM BB %if.end
Live Ins: %R4
Predecessors according to CFG: BB#0
%R24<def> = ADDrr %R4<kill>, %R4, %SR<imp-def,dead>
%SR<def> = POP %SP<imp-def>
RET %R24<imp-use>
BB#1: derived from LLVM BB %if.then
Predecessors according to CFG: BB#0
%R24<def> = CPYri 0
%SR<def> = POP %SP<imp-def>
RET %R24<imp-use>
Листинг 4.19: Окончательный список команд myDouble
| Виртуальный регистр | Физический регистр |
| %vreg0 | %R4 |
| %vreg1 | %R24 |
| %vreg2 | %R24 |
Таблица 4.1: Карта регистров для функции myDouble
4.2.4 Создание кода
Заключительного этапа бэкенда, сформировать список машинных инструкций с помощью ассемблера (получить объектный файл для платформы).
4.2.4.1 Ассемблер
Ассемблер сборки кода требует реализации нескольких пользовательских классов. Класс CJGAsmPrinter представляет подход, который позволяет формировать ассемблерный код. Класс CJGMCAsmInfo определяет некоторую базовую статическую информации для ассемблера, например, определить строку, используемую для комментариев:
CommentString = “//”;
Класс CJGInstPrinter содержит большинство важных функций, используемых ассемблером. Он импортирует код C++, который автоматически создается из AsmWriter TableGenbackend и определяет дополнительные необходимые методы. Одним из таких методов является printMemSrcOperand, который отвечает за печать собственного операнда memsrc, определенного в листинге 4.6. Реализация этого метода показана в листинге 4.20. Метод работает на абстрактном классе MCInst и выводит строковое представление операнда. Окончательный код для ассемблера для функции myDouble приведен в листинге 4.21. Ассемблер сборки добавляет полезные комментарии, а также комментирует метку любого базового блока, который не используется в качестве места перехода в ассемблерном коде.
// Печать memsrc (определенного в CJGInstrInfo.td)
// Это операнд определяет место для загрузки или хранения,
// смещения регистра с помощью непосредственного значения
void CJGInstPrinter::printMemSrcOperand(const MCInst *MI, unsigned OpNo, raw_ostream &O) {
const MCOperand &BaseAddr = MI->getOperand(OpNo);
const MCOperand &Offset = MI->getOperand(OpNo + 1);
assert(Offset.isImm() && "Expected immediate in displacement field");
O << "M[";
printRegName(O, BaseAddr.getReg());
unsigned OffsetVal = Offset.getImm();
if (OffsetVal) {
O << "+" << Offset.getImm();
}
O << "]";
}
Листинг 4.20: Реализация собственного метода printMemSrcOperand
myDouble: // @myDouble
// BB#0: // %entry
push r0
cmp r4, 0
jeq BB0_1
// BB#2: // %if.end
add r24, r4, r4
pop r0
ret
BB0_1: // %if.then
cpy r24, 0.
pop r0
ret
Листинг 4.21: Окончательный ассемблерный код для функции myDouble
4.2.4.2.2 Модуль записи объектов ELF
Пользовательский машинный код создается в виде объектного файла ELF. Как и в случае с ассемблером, для создания машинного кода необходимо реализовать несколько пользовательских классов. Класс CJGELFObjectWriter в основном служит оболочкой для своего базового класса, MCELFObjectTargetWriter, который отвечает за правильное форматирование файла ELF. Класс CJGMCCodeEmitter содержит большинство важных функций для выдачи машинного кода. Он импортирует код C++, который автоматически генерируется из эмиттера кода TableGen бэкенда. Этот бэкенд обрабатывает большую часть битового сдвига и форматирования, необходимого для кодирования инструкций, как показано в разделе 4.2.1.4. Класс CJGMCCodeEmitter также отвечает за кодирование пользовательских операндов, таких как операнд memsrc, определенный в листинге 4.6. Реализация метода, ответственного за кодирование этого пользовательского операнда с именем getMemSrcValue, показана в листинге 4.22.
// Кодировать memsrc (определенный в CJGInstrInfo.td)
// это операнд, который определяет место для загрузки или хранения, которое
// является регистром, смещенным на непосредственное значение
unsigned CJGMCCodeEmitter::getMemSrcValue(const MCInst &MI, unsigned OpIdx,
SmallVectorImpl<MCFixup> &Fixups,
const MCSubtargetInfo &STI) const {
unsigned Bits = 0;
const MCOperand &RegOp = MI.getOperand(OpIdx);
const MCOperand &ImmOp = MI.getOperand(OpIdx + 1);
Bits |= (getMachineOpValue(MI, RegOp, Fixups, STI) << 16);
Bits |= (unsigned)ImmOp.getImm() & 0xffff;
return Bits;
}
Листинг 4.22: Пользовательская реализация getMemSrcValue
Пользовательский операнд memsrc представляет 21 бит данных: 5 битов требуются для кодирования регистра и еще 16 битов для непосредственного значения. Они хранятся в одном значении, а затем разделяются кодом, автоматически созданным из TableGen. Использование этого пользовательского операнда можно увидеть в листинге 4.23, где показано определение формата инструкций для инструкций загрузки и хранения (как указано в разделе 3.3.1). Строка 7 показывает объявление, строка 11 показывает биты, используемые для значения регистра, и строка 13 показывает биты, используемые для непосредственного значения. Код эмиттера TableGen бэкенда для этого определения создает код C++, как показано в листинге 4.24. Этот код используется при написании машинного кода для инструкции загрузки. В строке 6 показано использование пользовательского метода getMemSrcValue. Строка 7 маскирует всё, кроме регистровых битов, и сдвигает их в правильное место в слове инструкции, а строка 8 делает то же самое, но для 16-битного непосредственного значения.
class LS_Inst<bits<5> opcode, dag outs, dag ins, string asmstr,
list<dag> pattern>
: InstCJG<outs, ins, asmstr, pattern> {
bits<5> ri;
bits<1> control;
bits<21> addr;
let Opcode = opcode;
let Inst{26-22} = ri;
let Inst{21-17} = addr{20-16}; // rj
let Inst{16} = control;
let Inst{15-0} = addr{15-0};
}
Листинг 4.23: Определение формата инструкций базовой загрузки и хранения
case CJG::LD: {
// op: ri
op = getMachineOpValue(MI, MI.getOperand(0), Fixups, STI);
Value |= (op & UINT64_C(31)) << 22;
// op: addr
op = getMemSrcValue(MI, 1, Fixups, STI);
Value |= (op & UINT64_C(2031616)) << 1;
Value |= op & UINT64_C(65535);
break;
}
Листинг 4.24: CodeEmitter TableGen выходной бэкенд для загрузки
Платформо-зависимые машинные инструкции помещаются в “.text” секцию ELF объектного файла. Используется собственный созданный ELF парсер и созданный дизассемблер для архитектуры CJG (см. раздел 5.3), результаты от дизассемблирования ELF файла можно увидеть ниже. Дизассемблированный код и машинный код (в виде файла памяти Verilog) показаны для функции myDouble в листингах 4.25 и 4.26. Это показывает, что ассемблерный код, созданный ассемблером (как показано в листинге 4.21), эквивалентен машинному коду, созданному модулем записи объектов.
push r0 // @00000000 00
cmp r4, 0 // @00000004 01
jeq label_0 // @00000008 18
add r24, r4, r4 // @0000000C 00
pop r0 // @00000010 00
ret // @00000014 00
label_0: cpy r24, 0 // @00000018 00
pop r0 // @0000001C 00
ret // @00000020 00
Листинг 4.25: Дизассемблированный машинный код для функции myDouble
@00000000 18000000 // push r0 @00000004 50080001 // cmp r4, 0 @00000008 28050018 // jeq label_0 @0000000C 46084000 // add r24, r4, r4 @00000010 20000000 // pop r0 @00000014 38000000 // ret @00000018 16010000 // label_0: cpy r24, 0 @0000001C 20000000 // pop r0 @00000020 38000000 // ret
Листинг 4.26: Машинный код функции myDouble